Python Class for Printing Single-Line Status Bars
When running a command line program that executes an iterable procedure, such as web scraping, it's usually helpful to print out the current status as the program runs. This is especially true when the program takes an extended period of time. For example, when scraping BoxRec I added a 15 second time delay between urls as they bounced me a few times for too many requests. This caused the program to take over an hour as it scraped a large number of fights for many boxers.
However, if you continually print status updates over many lines, it will clutter the output. Especially when you don't need that output once the program successfully completes a step in the iteration. A resolution for this is to write over the current output during each step.
To manage this easily, I created a SameLinePrinter class that logs the current line length and writes over it on consecutive prints. This takes care of the status line overhead so you can focus on the data science. Below is the class script.
import sys
import time
class SameLinePrinter:
def __init__(self, previous_line_length=0):
self.previous_line_length = previous_line_length
def print_line(self, line):
print('\r' + ' ' * self.previous_line_length + '\r', end='')
print(line, end='')
sys.stdout.flush()
self.previous_line_length = len(line)To illustrate, let's take a look at how it works over a loop.
printer = SameLinePrinter()
for i in range(1, 101):
time.sleep(1)
printer.print_line("Test: {:>3} / 100".format(i))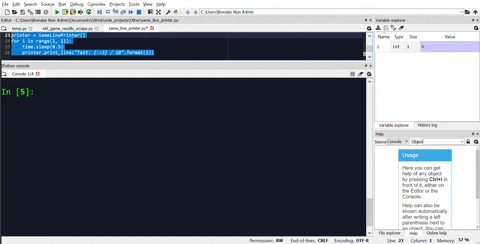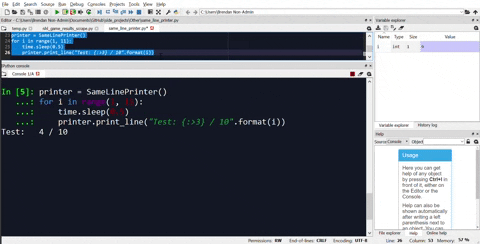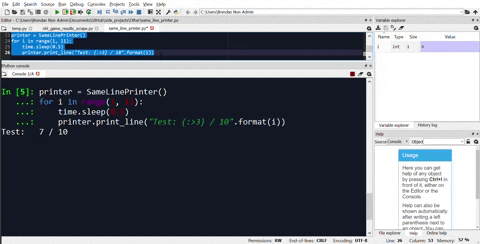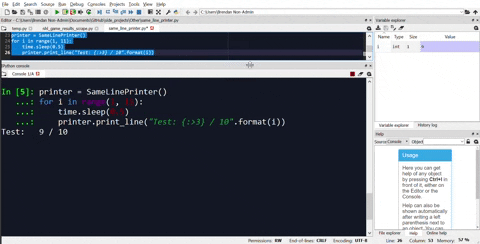
As an alternative, there are progress bar modules available as well. My recommendation would be tqdm. Here is the same example of how to use it for the same loop.
from tqdm import tqdm
for i in tqdm(range(1, 101)):
time.sleep(1)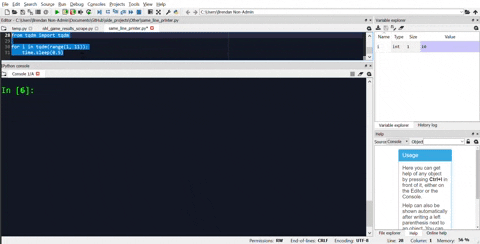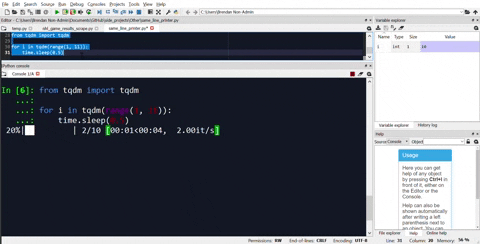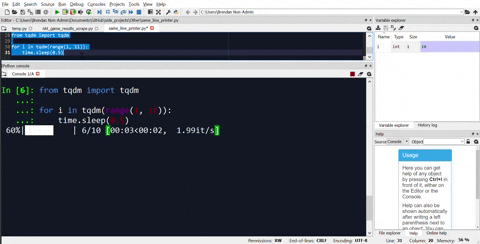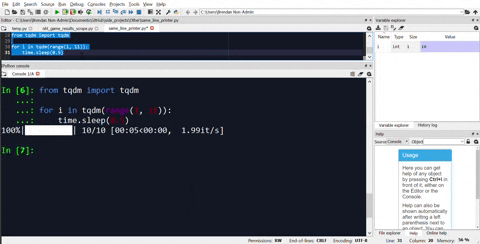
Thanks for reading!