Parsing XML to Visual the Yield Curve
One day you might find yourself looking to get some data and all the sudden you run square into an application that only delivers XML!

WTF is XML and why do we need XML you might ask? The idea of XML is to create a format to get data from point A to point B. Except in this game, point A and point B are computers, or servers, and their vernacular isn't plain english. They do happen to be fluent in XML though!
To quote A Technical Introduction to XML, found here (a great bedside read for those interested or masochistic in nature), "XML is a markup language for documents containing structured information."
Whoa. That's a lot to unpack in one sentence.
To pump the breaks for a second, structured information contains both content (words/pics/etc.) and meaning about the role that content plays (title, section heading, footnote, etc.) Markup language is defined as "a mechanism to identify structures in a document. The XML specification defines a standard way to add markup to documents."
Basically XML is a way to set the rules for the info (data!) you are transmitting and also that info itself. For example, transmitting sport scores (home team, away team, score, etc.) would be different than stock data (price, volume, etc.).
Is XML the same as HTML? Short answer, no.
HTML's tag semantics and tag set are fixed (e.g. <p> for paragraphs). These are determined by the W3C, along with browser vendors and the WWW community. XML, on the otherhand, doesn't specific either tag semantics or tag sets. The presentation of an XML document is dependent on a stylesheet that defines the tags.
Okay, cool, but why the do we need this XML stuff? To quote our favorite article from above "XML was created so that richly structured documents could be used over the web".
That's enough theory. Let's take a look at the XML we're dealing with today.
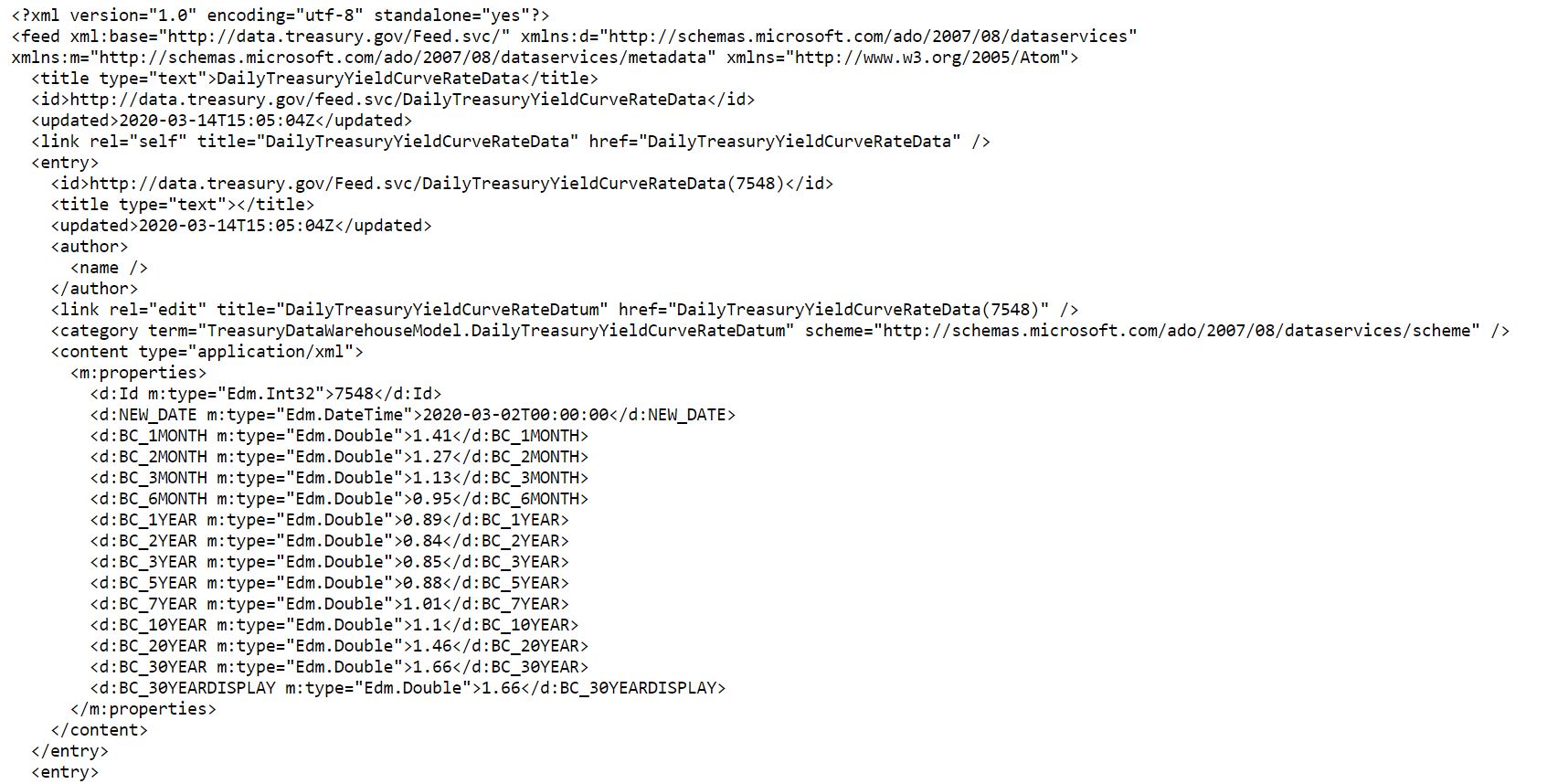
The first line tells us the XML versions. The second line tells us the namespaces, or where the tags are defined (tags can be defined in multiple tags sets, hence the need for namespaces). Then we hit the actual juice of the stuff.
The third line is the title tag and tells us we are dealing with Treasury Yield Curve Rate Data. For each date we have an entry. The entry contains information about when this data was updated, its ID and most importantly its content tags, which is are our data is found.
We see each content tag has a properties tag, with multiple tags for each datapoint (<Id>, <NEW_DATE>, <NEW_DATE>, etc.). Here we can find the date and yield for each Treasury Security. The yields themselves are found within each tag. Additionally, they have provided us with the datatype in the type attribute within each tag. How thoughtful!
So now that we've mastered the structure of this XML document, what do we do with it? Luckily python has an XML toolset named ElementTree to help us parse all this. I used the below script to parse the XML and return the data structured in json, which is easier for our d3 app to use. This was plugged into my API blueprint in this flask API itself. The API route is then called by our d3 visual here. Highly recommend checking out the tool.
Enjoy!